Best Frontier AI Model of 2025, and the winner is... Gemini 3? Grok 4.2? ChatGPT 5.2? Claude Opus 4.5?
The Age of Orchestration: A Strategic Analysis of Frontier AI Systems in Q4 2025

Do you have AI Benchmark fatigue? Do you grow tired of weekly updates that declare the new release of an AI model the best?
The era of the standalone large language model is over. As we close out 2025, the competitive frontier in artificial intelligence has shifted from raw model capability to something more nuanced and powerful: orchestrated systems that combine models with tools, agents, and multi-step reasoning. Let's examine where the major players stand, how we measure progress, and what the future holds for enterprises navigating this new landscape.
The Paradigm Shift: From Standalone Models to Orchestrated Systems

The End of an Era
The "Large Language Model" paradigm, once focused on static knowledge and parameter counts, has reached its logical conclusion. The competitive frontier is now defined by "System 2" agentic reasoning, inference-time compute, and multi-agent collaboration. Simply training a bigger model on more data no longer guarantees leadership.
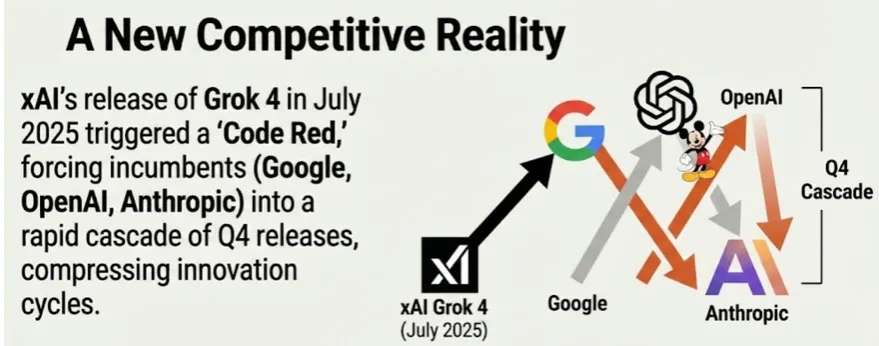
A New Competitive Reality
xAI's release of Grok 4 in July 2025 triggered what many in the industry called a "Code Red," forcing incumbents like Google, OpenAI, and Anthropic into a rapid cascade of Q4 releases. This compression of innovation cycles has created an environment where no single company can rest on its laurels for more than a few months. Then Gemini 3 came out and OpenAI issued a "Code Red" which harkens back the "Code Red" that Google issued when ChatGPT started winning the hearts and minds of consumers and corporations alike.
xAI Grok -> Google Gemini -> Anthropic Claude -> OpenAI ChatGPT seem to release models regularly which everyone states is the best. Which is the best?
Performance is Now Systemic
Traditional benchmarks have become saturated. The new adversarial evaluations, such as Humanity's Last Exam (HLE), reveal a critical truth: peak performance is achieved not by the model alone but by the system orchestrating it with tools and agents. A model's score in isolation tells only part of the story.
Economic Bifurcation
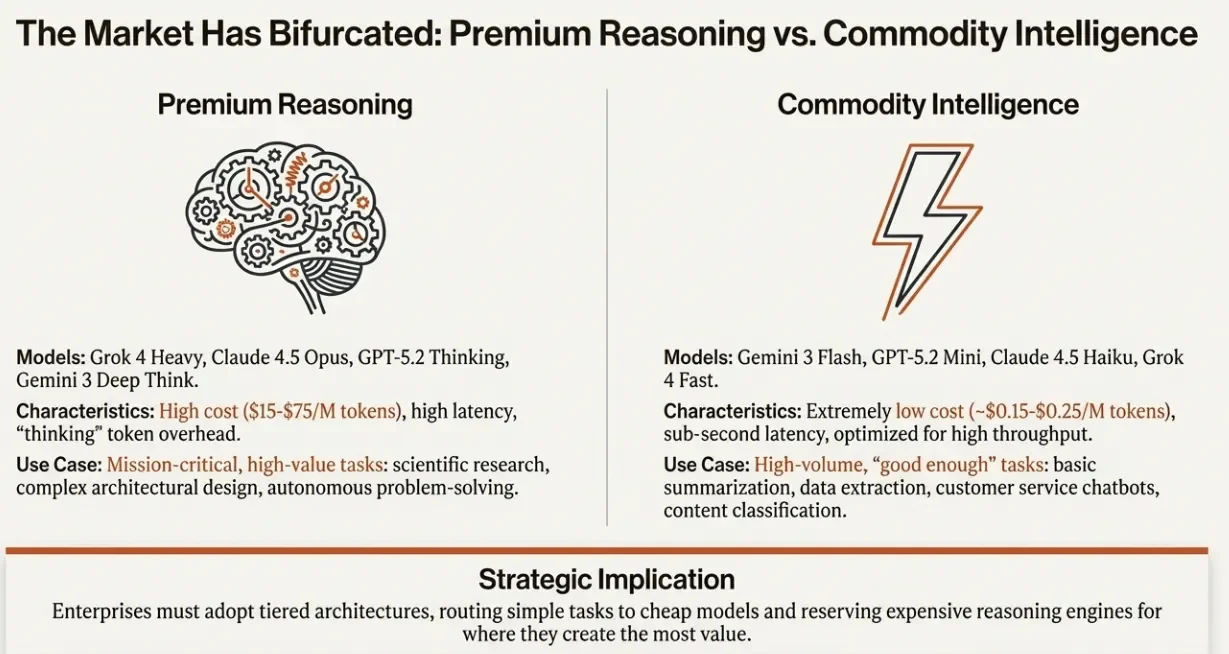
The market has split into two distinct segments:
- "Commodity Intelligence" offers cheap, fast models suitable for high-volume tasks
- "Premium Reasoning" provides expensive, deliberate "thinking" models designed for complex problem-solving
Enterprises must now develop tiered adoption strategies to navigate this divide effectively.
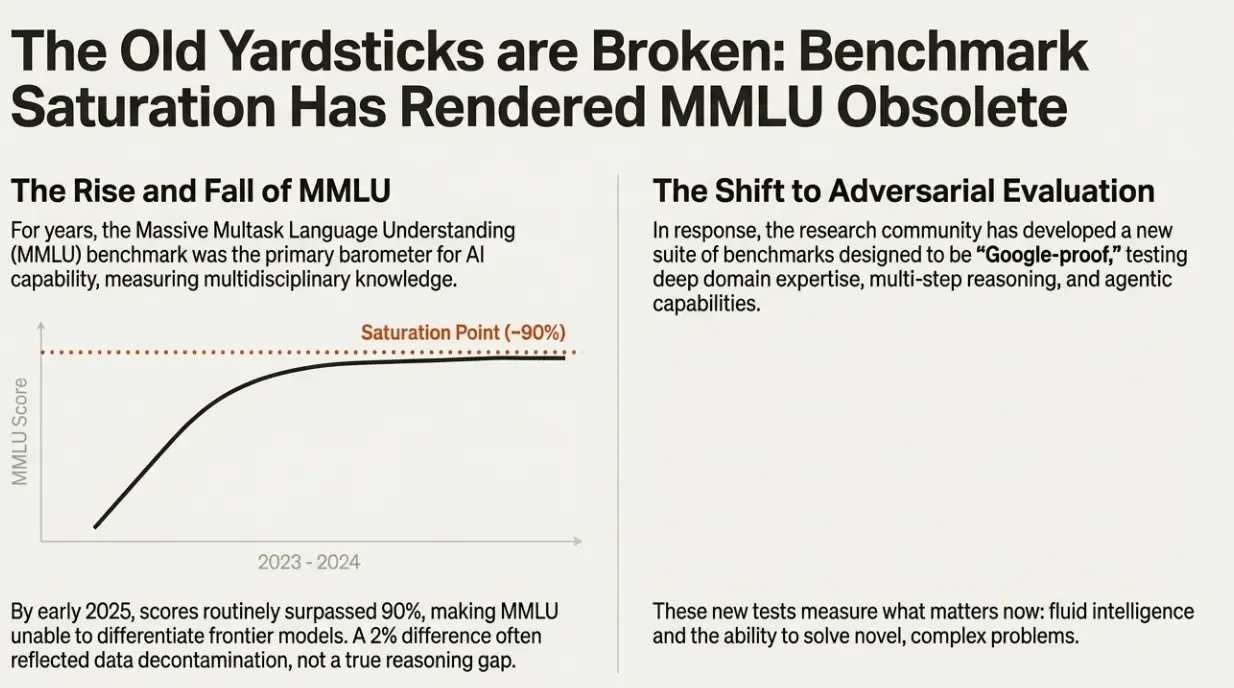
The Old Yardsticks are Broken: Benchmark Saturation Has Rendered MMLU Obsolete
The Rise and Fall of MMLU
For years, the Massive Multitask Language Understanding (MMLU) benchmark served as the primary barometer for AI capability, measuring multidisciplinary knowledge across dozens of subjects. By early 2025, however, scores routinely surpassed 90%, making MMLU unable to differentiate frontier models. A 2% difference between models often reflected data decontamination practices rather than any true reasoning gap.
The Shift to Adversarial Evaluation
In response, the research community developed a new suite of benchmarks designed to be "Google-proof," testing deep domain expertise, multi-step reasoning, and agentic capabilities. These new tests measure what truly matters now: fluid intelligence and the ability to solve novel, complex problems that cannot be answered through simple retrieval.
Meet the New Arbiters of Frontier Intelligence
The benchmarks that now matter paint a very different picture of model capabilities:
GPQA Diamond measures deep scientific synthesis through "Google-proof" questions created by PhDs that require genuine reasoning rather than retrieval. It has become the standard for graduate-level domain expertise.
AIME/MathArena tests creative mathematical logic through Olympiad-level integer-answer problems requiring novel solution paths. It serves as the crucible for formal, multi-step logical reasoning.
SWE-Bench evaluates agentic productivity in software engineering by measuring a model's ability to resolve real GitHub issues in complex Python codebases. It provides a direct predictor of a model's commercial utility as an autonomous developer. Does this mean if the model does well, it will enable the best Java coding agent or the best Rust coding agent? Probably not. But we don't have a test for that so this is the closest we have.
ARC-AGI assesses fluid intelligence and skill acquisition through novel visual grid puzzles that can only be solved from 2-3 examples. It remains the best proxy for adaptability and a key indicator for artificial general intelligence.
Humanity's Last Exam (HLE) represents the frontier of human academic knowledge through 3,000 multimodal questions designed to be unsolvable by search or shortcuts. It is the "final boss" benchmark that exposes the gap between model and system intelligence.
Humanity's Last Exam Proves the System is Smarter Than the Model

The HLE results reveal the most important insight of 2025: orchestration matters more than raw intelligence. Consider the scores:
- Gemini 3 Pro leads with 37.5%, demonstrating high native intelligence
- GPT-5.2 follows at 33%, with Claude 4.5 at 25.2%
But here is where things get interesting: Grok 4 Heavy scores just 26% in text-only mode, yet jumps to 50.7% when equipped with tools and agents, crossing the superhuman performance threshold.
The massive performance gap between "Text-Only" and "With Tools" provides empirical proof that the future of AI is orchestration. Grok 4 Heavy's breakthrough score was achieved not by a better model but by a better system that integrates multi-agent debate and tool use.
The Frontier is Defined by Four Competing Philosophies

The AI landscape is not defined by a single triumphant model or a clear-cut victor among the titans. Instead, we face a tapestry woven from distinct philosophies.
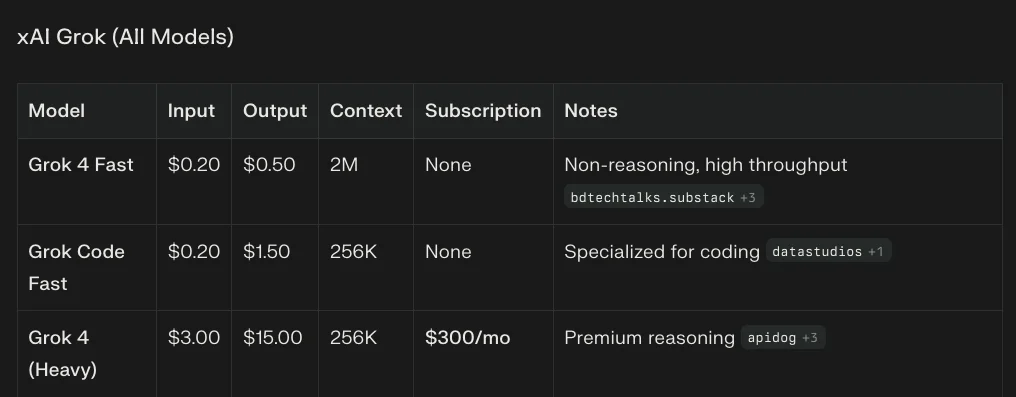
xAI: Brute-Force Compute and Multi-Agent Orchestration
xAI's approach leverages massive GPU clusters and inference-time compute to solve reasoning tasks through multi-agent consensus, trading latency for accuracy. Grok 4 Heavy spawns up to 32 parallel agents to debate and verify solutions.
Strengths: 100% on AIME, 50.7% on HLE with tools, and unrivaled real-time knowledge through direct integration with the X platform's live data stream.
Weaknesses: The multi-agent approach is extremely slow (taking seconds to minutes) and computationally expensive, while multimodal capabilities lag behind native multimodal competitors.
Google: Native Multimodality and Long-Context Dominance

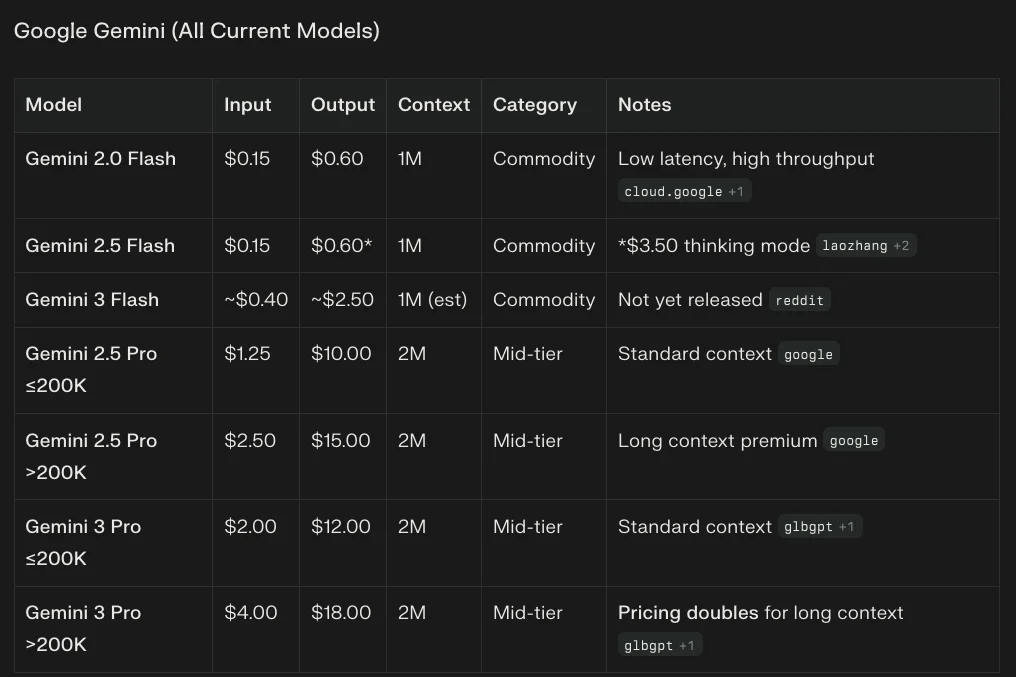
Google has built models trained from the ground up on video, audio, and text to achieve superior understanding of mixed media, deeply integrated into the Workspace ecosystem. Gemini 3 Pro features "Deep Think" and encrypted "Thought Signatures" for persistent reasoning, while Gemini 3 Flash offers a highly optimized, low-cost option for price-performance leadership. The defining feature is a standard 1M+ token context window with extremely low "haystack" retrieval error.
Strengths: State-of-the-art multimodal reasoning (81.0% on MMMU-Pro), the highest factuality rating on DeepMind's FACTS benchmark (68.8% versus GPT-5's 61.8%), and deep ecosystem integration with Google Workspace.
Weaknesses: Coding specialization, where Google faces stiff competition from Claude 4.5's "human-like" coding intuition.
OpenAI: Agentic Reliability and "System 2" Scaling
OpenAI focuses on production-grade agentic workflows and developer APIs, making "thinking" a core, scalable product feature to maintain ecosystem leadership. GPT-5.2 offers a 400k context window and a class-leading 128k token output limit, enabling generation of entire codebases in a single pass.
Strengths: State-of-the-art performance for agentic coding (making it the engine of choice for autonomous developer agents like Devin and Windsurf), 100% on AIME, and mature developer APIs with the Responses API and Realtime API setting industry standards.
Weaknesses: High cost ($14/M output tokens) with the "Thinking" process adding significant hidden token overhead, plus what some observers call an "evaporated lead"; the rapid iteration from 5.1 to 5.2 was a reactive move to catch Gemini 3.
Anthropic: "Character," Safety, and Coding Excellence
Anthropic has carved a defensible niche as the most steerable, efficient, and developer-friendly model, excelling in tasks requiring nuance and coding intuition. The Claude 4.5 family includes:
- Opus: Premium model optimized for complex reasoning and architectural design
- Sonnet: The workhorse balancing speed and intelligence, widely used in coding IDEs
- Haiku: Fast, low-cost option for high-throughput tasks
Strengths: Coding and terminal mastery (holding the record on Terminal-Bench Hard), superior writing quality with less formulaic "AI-ese," and reasoning efficiency that achieves top-tier performance with significantly fewer tokens than competitors.
Weaknesses: Trailing in multimodality (lagging Gemini 3 Pro in native video and audio benchmark performance) and a smaller context window (200k versus OpenAI's 400k and Google's 1M+, though recently Claude Sonnet 4.5 can use up to 1MB).
Head-to-Head: The Benchmarks Tell the Story
The Math Singularity
On AIME (Math Olympiad), we have reached functional perfection in high-school Olympiad math:
- GPT-5.2 (Thinking) and Grok 4 Heavy both achieve 100%
- Gemini 3 Pro at approximately 94%
- Claude 4.5 Opus at 90%+
The frontier must now shift to research-level mathematics.
The Science Differentiator
On GPQA Diamond (PhD Science), the real battle is in scientific synthesis:
- GPT-5.2 leads at 93.2%
- Gemini 3 Pro at 91.9%
- Claude 4.5 Opus at 90%
- Grok 4 Heavy at 88%
GPT-5.2 holds a narrow lead, likely due to superior integration of Python tools for simulation and verification during its reasoning process.
Native Intelligence vs. Systemic Power
The HLE and SWE-Bench results reveal different model personalities:
- Gemini 3 Pro is the most "book smart" model, achieving the highest score on HLE without assistance at 37.5%. It simply knows more.
- Grok 4 Heavy is the best "system user," leveraging its multi-agent system and tools to brute-force solutions and achieve the highest overall HLE score at 50.7%.
- Claude and GPT-5.2 are the "efficiency kings" in practical coding (SWE-Bench), with Claude often achieving state-of-the-art results with lower token usage, making it the most efficient choice for long-running agentic tasks.
The Market Has Bifurcated: Premium Reasoning vs. Commodity Intelligence
Premium Reasoning
Models in this tier include Grok 4 Heavy, Claude 4.5 Opus, GPT-5.2 Thinking, and Gemini 3 Deep Think.
Characteristics: High cost ($15-$75/M tokens), high latency, and "thinking" token overhead.
Use case: Mission-critical, high-value tasks: scientific research, complex architectural design, and autonomous problem-solving.
Commodity Intelligence
Models here include Gemini 3 Flash, GPT-5.2 Mini, Claude 4.5 Haiku, and Grok 4 Fast.
Characteristics: Extremely low cost (approximately $0.15-$0.25/M tokens), sub-second latency, and optimization for high throughput.
Use case: High-volume, "good enough" tasks: basic summarization, data extraction, customer service chatbots, and content classification.
Strategic Implication: Enterprises must adopt tiered architectures, routing simple tasks to cheap models and reserving expensive reasoning engines for where they create the most value. A one-size-fits-all approach to model selection is no longer viable.
The True Cost of Intelligence Includes the "Thinking" You Don't See

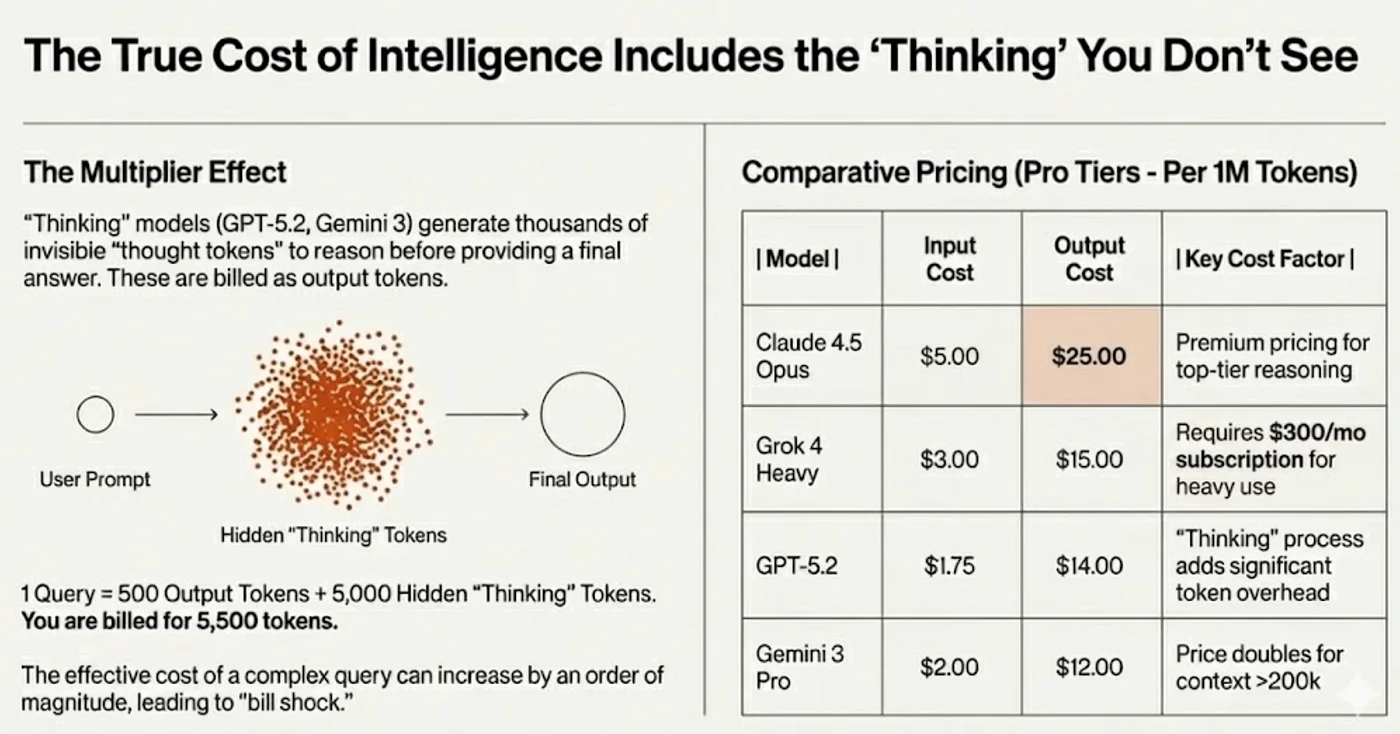
The Multiplier Effect
"Thinking" models (GPT-5.2, Gemini 3) generate thousands of invisible "thought tokens" to reason before providing a final answer. These are billed as output tokens. A single query might show 500 output tokens but actually consume 5,500 tokens when hidden thinking is included. The effective cost of a complex query can increase by an order of magnitude, leading to what some have called "bill shock."
Comparative Pricing (Pro Tiers, Per 1M Tokens)
| Model | Input | Output | Notes |
|---|---|---|---|
| Claude 4.5 Opus | $5 | $25.00 | Premium pricing for top-tier reasoning |
| Grok 4 Heavy | $3.00 | $15.00 | Requires $300/mo subscription for heavy use |
| GPT-5.2 | $1.75 | $14.00 | "Thinking" process adds significant token overhead |
| Gemini 3 Pro | $2.00 | $12.00 | Price doubles for context >200k |
The Intelligence Price Collapse

Claude Opus 4.5 represents a structural shift in AI economics:
- 21% intelligence increase while 67% cheaper
- Uses 48-76% fewer tokens than competing reasoning models
- Compound savings: Lower base price + higher token efficiency
- Opus 4.5 at $10 blended rivals o1-pro at $131 on many benchmarks
This breaks the historical pattern and suggests efficiency is the new scaling law. Anthropic achieved this through architectural improvements rather than runtime reasoning overhead.
Additional Cost Optimization
There are ways to save money too. Some models allow the use of:
Prompt Caching: Store frequently-used context (system prompts, documentation, examples) for 90% savings on repeated queries
Batch API: Non-urgent workloads get 50% discount with 24-hour turnaround
Cached Input Tokens can be a significant savings:
- Claude: 90% discount
- GPT-5: $0.063/M (vs $0.625 standard, 10x)
- Gemini: 75% discount
Real-world costs can be 10-20x lower than headline pricing with proper architecture. This is tactics and strategy.
2026: The Battle is for the Platform, Not Just the Model
Google: The Workspace Moat
Google's strategy leverages dominance in productivity software through native integration in Docs, Drive, and Gmail; grounding with Google Search and Maps to solve hallucination; and "Deep Research" agents for knowledge workers.
OpenAI (+ Microsoft): The Agentic Standard
OpenAI and Microsoft aim to build the default operating system for AI agents through state-of-the-art developer experience with Responses and Realtime APIs, deep integration with Azure and Databricks for enterprise data, and positioning as the engine of choice for autonomous coding tools.
Anthropic: The Developer's Choice
Anthropic's strategy focuses on steerability, safety, and computer use through Model Context Protocol (MCP) as a data standard and enterprise "System Cards" for guardrails, making it the preferred choice for regulated industries like legal and healthcare.
Claude 4.5 Opus cost 65% of what Claude 4.0 Opus cost. The models get less expensive and more powerful. And Claude 4.5 Sonnet often outperforms Opus 4.0 whilst Haiku 4.5 often outperforms Sonnet 4.0.
xAI: The Wild Card
xAI aims to create a unique consumer-enterprise hybrid via vertical integration through exclusive, real-time data access from the X platform (providing an edge in finance and media) and rapid consumer rollout via "SuperGrok" with enterprise APIs catching up.
Conclusion: The Final Exam Was Not Passed by a Model. It Was Passed by a System.
Three key insights emerge from this analysis:
Context is King. There is no single "best" model, only the best model system for a specific task. Gemini for media, Claude for coding, Grok for raw reasoning, GPT-5 for agentic development; each has its place.
Inference is the New Training. The key to unlocking capability is now "System 2" scaling: letting models "think" longer at inference time. This makes the cost-per-query a strategic, variable decision rather than a fixed infrastructure cost.
The Future is Orchestration. The most critical capability is no longer parameter count but the ability to use tools (Python, Browser, Terminal). The future belongs to those who build the scaffolding that allows models to act as autonomous agents.
The era of the standalone LLM is over. Welcome to the Age of Orchestration.
The models continue to leapfrog each other and continue to specialize. Take every benchmark with a grain of salt because the benchmarks are limited in what they can test for and one thing for sure is your results will vary for your use cases.
In this tight race, there is no winner except for you the consumer.
This analysis reflects the state of frontier AI systems as of Q4 2025. Given the pace of innovation, expect significant developments in the months ahead. In other words, this will age like milk not wine.
About the Author
Rick Hightower is a technology executive and data engineer with extensive experience at a Fortune 100 financial services organization, where he led the development of advanced Machine Learning and AI solutions to optimize customer experience metrics. His expertise spans both theoretical AI frameworks and practical enterprise implementation.
Mr. Hightower holds TensorFlow certification and has completed Stanford University's Machine Learning Specialization. His technical proficiency encompasses supervised learning methodologies, neural network architectures, and AI technologies, which he has leveraged to deliver measurable business outcomes through enterprise-grade solutions.
Connect with Rick Hightower on LinkedIn or Medium for insights on enterprise AI implementation and strategy.
Community Extensions & Resources
The Claude Code community has developed powerful extensions that enhance its capabilities. Here are some valuable resources from Spillwave Solutions:
Integration Skills
- Notion Uploader/Downloader: Seamlessly upload and download Markdown content and images to Notion for documentation workflows
- Confluence Skill: Upload and download Markdown content and images to Confluence for enterprise documentation
- JIRA Integration: Create and read JIRA tickets, including handling special required fields
Advanced Development Agents
- Architect Agent: Puts Claude Code into Architect Mode to manage multiple projects and delegate to other Claude Code instances running as specialized code agents
- Project Memory: Store key decisions, recurring bugs, tickets, and critical facts to maintain vital context throughout software development
- Claude Agents Collection: A comprehensive collection of 15 specialized agents for various development tasks
Visualization & Design Tools
- Design Doc Mermaid: Specialized skill for creating professional Mermaid diagrams for architecture documentation
- PlantUML Skill: Generate PlantUML diagrams from source code, extract diagrams from Markdown, and create image-linked documentation
- Image Generation: Uses Gemini Banana to generate images for documentation and design work
- SDD Skill: A comprehensive Claude Code skill for guiding users through GitHub's Spec-Kit and the Spec-Driven Development methodology
- PR Reviewer Skill: Comprehensive GitHub PR code review skill for Claude Code
AI Model Integration
- Gemini Skill: Delegate specific tasks to Google's Gemini AI for multi-model collaboration
- Image_gen: Image generation skill that uses Gemini Banana to generate images
Explore more at Spillwave Solutions - specialists in bespoke software development and AI-powered automation.
Discover AI Agent Skills
Browse our marketplace of 41,000+ Claude Code skills, agents, and tools. Find the perfect skill for your workflow or submit your own.